O mecanismo de Attention dos Transformers tem sido uma revolução no processamento de linguagem natural, a exemplo do ChatGPT. O artigo “Introdução aos Transformers: Uma Revolução na Inteligência Artificial“ explora detalhadamente essa revolução e seu funcionamento.
Já para o tratamento de imagens, a técnica que tem sido amplamente explorada atualmente são Vision Transformers (ViTs). Essa tecnologia aborda de forma inovadora o campo da visão computacional, inspirada na arquitetura dos Transformers, e podem ser especialmente úteis no reconhecimento de imagens. Em termos simples, o uso de Transformers em imagens envolve a divisão da imagem em pequenos patches que são então tratados como sequências de entrada, de forma semelhante ao texto em NLP, o bom e velho “dividir para conquistar”.
Ao contrário das redes neurais convolucionais (CNNs) tradicionais, que operam em blocos de pixels, os ViTs dividem a imagem em pequenos patches e os tratam como uma sequência de entrada. Cada patch é transformado em um vetor de características, que é então submetido a múltiplas camadas de autoatenção, permitindo que o modelo pondere a importância de diferentes partes da imagem para tarefas específicas.
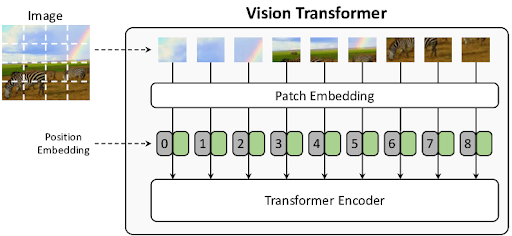
Figura 1: Codificação do transformador de visão.
Essa abordagem permite que o modelo focalize áreas relevantes da imagem durante a análise, o que é crucial para tarefas como classificação e detecção de objetos e segmentação semântica. A capacidade dos ViTs de capturar relações de longo alcance entre diferentes partes da imagem, juntamente com sua flexibilidade para lidar com diferentes tamanhos de entrada, contribui para um desempenho robusto em uma variedade de cenários visuais.
Uma das principais vantagens dos ViTs é sua capacidade de lidar com imagens de diferentes tamanhos sem precisar de alterações na arquitetura, graças à sua abordagem baseada em atenção. Isso os torna altamente flexíveis e adaptáveis a uma variedade de cenários visuais, tornando-os eficazes em uma ampla gama de aplicações. Além disso, os ViTs têm mostrado resultados promissores mesmo com conjuntos de dados de treinamento menores, o que os torna uma escolha atraente em ambientes onde os dados podem ser limitados.
Outra característica importante dos ViTs é sua capacidade de capturar informações contextuais de toda a imagem, em vez de se concentrar apenas em pequenas regiões locais. Isso os torna robustos em situações onde a relação entre diferentes partes da imagem é crucial para a tarefa em questão.
Em resumo, os Vision Transformers representam uma abordagem poderosa e flexível para o processamento de imagens, aproveitando os princípios dos Transformers para alcançar desempenho e eficiência computacional aprimorados em uma variedade de tarefas de visão computacional.
Na Norven temos explorado técnicas como essa para aumentar automatizar processos que eram absolutamente manuais até recentemente, contribuindo efetivamente para o aumento da eficiência da nossa equipe. Também estamos experimentando técnicas como essa em soluções para nossos clientes, seguindo nossa aptidão para inovação de dados em setores complexos.